The Ash AI Tax
For months I’ve had a nagging suspicion that I couldn’t quite prove. Every time I pointed a coding agent at our Ash codebase, it seemed to chew through tokens faster than when it worked on plain Phoenix. Not a little faster. Noticeably. I assumed I was imagining it — confirmation bias dressed up as a hunch — and filed it under “things I’ll never get around to checking.”
Then I got around to checking. I built the same feature, to the same passing test suite, in two stacks — idiomatic Ash and plain Phoenix + Ecto — and had the same agent build it five times each. The result was bigger than my hunch:
Building an identical feature, Claude (Opus 4.7) used +162% more tokens in Ash than in plain Ecto. Codex (GPT-5.5) used +90% more. The effect showed up on both agents.
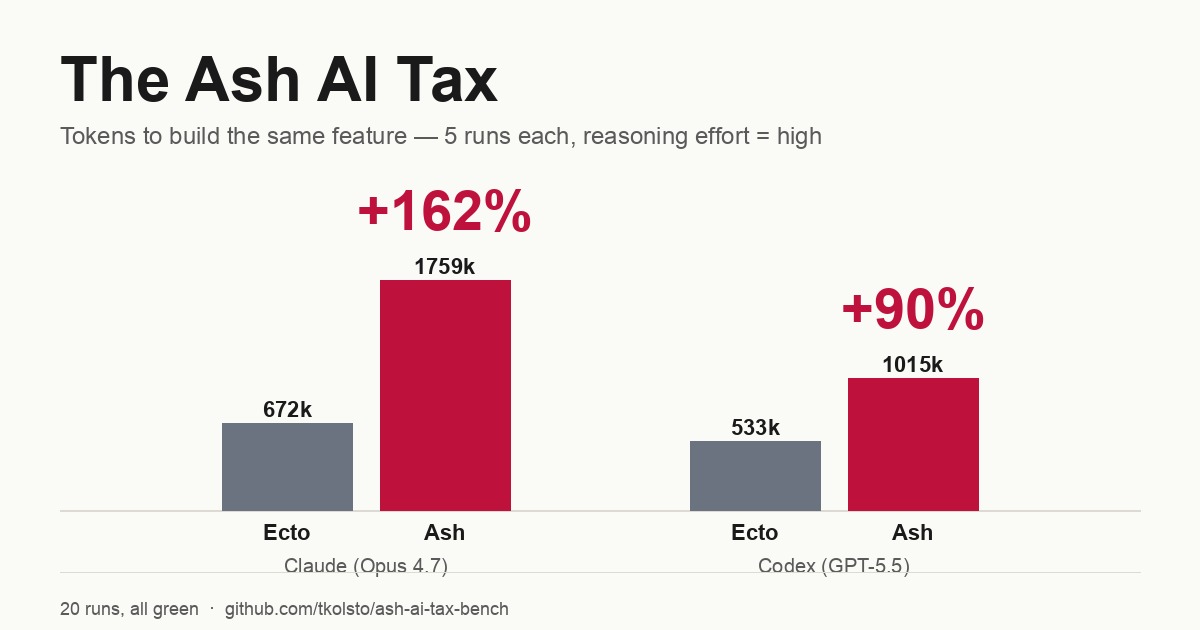
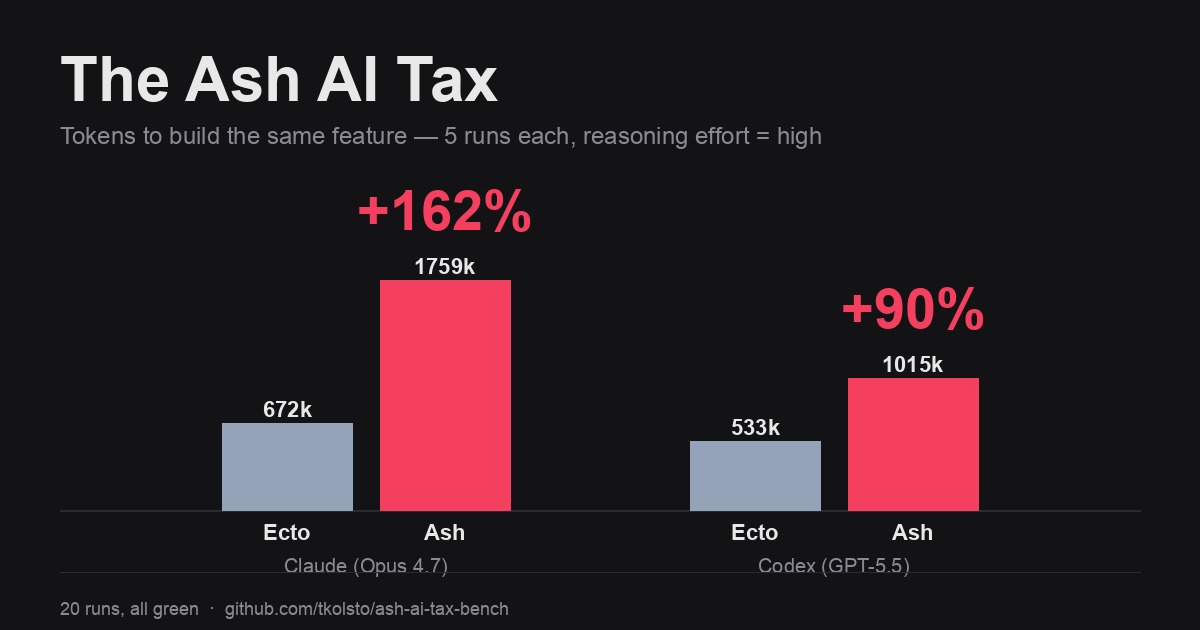
I’d have bet on 25%. It was closer to 2.6x.
Why this is worth measuring
We’ve quietly crossed a line where most code is now written with an agent in the loop. And tokens aren’t free — they’re money, they’re latency, and they’re pressure on a finite context window. Which means your framework choice now has a dimension nobody puts on the comparison table: how expensive is it for an AI to work in?
That’s an uncomfortable question, because the answer might disagree with everything that makes a framework pleasant for humans. Ash is, for a certain kind of problem, genuinely delightful to work in. The question isn’t whether it’s good. It’s whether the thing that helps me costs the robot extra — and by how much.
The experiment
I wanted a number I could defend, not a vibe. So I pinned everything I could.
The task: a small Support-ticket domain — a Ticket with validations, a Comment
relationship, an assignee, custom close/reopen actions with state-transition guards,
and authorization (assignee-or-admin can close, admin-only can reopen). Enough surface to
exercise the parts of Ash people actually reach for, not toy CRUD.
The trick that makes it a fair fight: I defined the contract at a plain Elixir module
boundary (Support.create_ticket/2, Support.close_ticket/2, and friends) and wrote one
framework-agnostic ExUnit suite against it. That boundary is idiomatic for both sides —
an Ash code_interface and an Ecto context function expose the exact same six functions.
“Done” meant the suite went green, the project compiled, and the linter was happy. No
partial credit, no vibes.
The controls:
- Same agent, same model, same prompt for both stacks. Only the framework differed.
- Reasoning effort pinned to
highon every single run — identical across frameworks and across agents. (“Does the agent reason more in Ash?” is one of the things I wanted to measure, so I wasn’t about to let the effort setting drift.) - The Ash side got its idiomatic context — the
usage_rulesAGENTS.md, all 1,556 lines of it — exactly as a real Ash developer’s agent would. The Ecto side got nothing special, because it doesn’t need anything special; it’s already in the model’s bones. - 5 runs per cell, fresh checkout each time, and — crucially — I verified green myself after every run rather than trusting the agent’s word for it.
Then I did the same thing with two different agents — Claude Code and Codex — because “it replicates across models” is the difference between a finding and an anecdote.
The whole harness — spec, the shared suite, both reference implementations, the runner, and the raw per-run token logs — is open source so you can pick it apart or reproduce it: github.com/tkolsto/ash-ai-tax-bench.
How much more does Ash cost in tokens?
About 2× more — verified across 20 runs, every one reached green:
| Agent | Ecto (avg tokens) | Ash (avg tokens) | Ash tax | Turns: Ecto → Ash |
|---|---|---|---|---|
| Claude (Opus 4.7) | 671,886 | 1,758,599 | +162% | 22.4 → 31.0 |
| Codex (GPT-5.5) | 533,001 | 1,015,218 | +90% | 23.2 → 32.8 |
A few things I want to be honest about. Per-run variance is high — Codex’s Ash runs ranged from 526k to 1.44M tokens — so treat these as “roughly 2x,” not “162.0%, QED.” But the direction is rock solid: there was no run, on either agent, where Ash came out cheaper. And the deltas barely budged between my initial 3-run pilot and the full 5-run matrix (Claude 179% → 162%, Codex 85% → 90%), which is what you want to see before you believe a number.
Both agents also needed about 40% more turns to get Ash green. That matters, and it’s the thread that unravels the whole thing.
Where do the extra tokens actually go?
Here’s the part I find genuinely interesting, because it’s not what I’d have guessed.
It’s not that Ash code is bigger. The diffs the agents produced were comparable in size — in some cases the Ash version was smaller. The tax isn’t in what the agent writes. It’s in what the agent has to understand before it can write anything correct.
I saw it concentrate in three places.
Context it has to haul in. Ash is a framework you cannot bluff. To write a correct resource the agent pulls in the usage rules, the resource definitions, the extensions. On Claude this is brutal in a quietly compounding way: Claude re-reads its cached context on every turn, so a bigger starting context multiplied by more turns is a multiplier on a multiplier. That’s most of why Claude’s tax (+162%) towers over Codex’s (+90%) — same phenomenon, different token accounting.
Reasoning, not typing. With effort pinned high, the agent visibly spent more thinking on Ash — working out which declarative knob produces the imperative behavior the test wants. Ecto is “write a query.” Ash is “which action, which change, which validation, which policy, and will it survive atomic execution.”
The “that’s not how Ash works” tax. This is the retry loop, and I have receipts. Watching the reference build, the friction was almost never the domain logic — it was bending the framework to a specific contract:
- A
code_interfacenamedcreate_ticketcollides with a hand-writtencreate_ticket/2. You learn to define internal interfaces and wrap them. - The suite wants
get_ticketto return{:error, :not_found}. Ash returns a NotFound wrapped inside anAsh.Error.Invalid. So you write an error-normalization shim. - Reading the current
statusto guard a transition trips Ash 3’sdefault_actions_require_atomic? true. The fix (require_atomic? falseplus a guard validation) is in the usage rules — but an agent that didn’t read that section earns a baffling atomic-validation error and a round-trip to recover. - Policies: consecutive
authorize_ifs are OR, not AND. Get that mental model wrong and your authorization tests fail in ways that look like logic bugs.
None of this is hard once you know it. That’s exactly the point. It’s a large surface of framework-shaped knowledge, and every gap in the agent’s understanding is paid for in tokens.
So is it worth it?
This is where I have to be fair, because I like Ash and I’m not writing a hit piece.
Here’s the tension in one sentence: for a human, Ash often means writing less code; for an AI, it means understanding more before writing anything. Those pull in opposite directions, and which one dominates depends on who — or what — is at the keyboard.
What the tax buys you is real: declarative actions, policies that live next to the data they guard, generated APIs, a mountain of correctness you don’t have to hand-roll or maintain. On a long-lived system with a team, that leverage is worth a lot more than a pile of tokens. The tax is also front-loaded comprehension, not ongoing bloat — it’s the cost of the agent learning the framework’s shape, not a per-line penalty forever.
But if you’re spinning up something small, or you’re leaning hard on agents to move fast, or you’re watching a token bill — “2x the tokens, every feature” is a number that belongs in the decision, right next to all the reasons Ash is lovely.
How to shrink the Ash AI tax
The good news is that the biggest cost — comprehension — is the most fixable, because you can hand the agent the understanding instead of making it pay to rediscover it.
- Invest in
usage_rules. This is the single highest-leverage move. The whole tax is the agent learning Ash’s shape; a good, current usage-rules file is that shape, pre-loaded. Keep it synced. (Fair warning: theusage_rules.synctooling itself has sharp edges — it cost me a few iterations during this very experiment.) - Reach for
ash_ai/ tidewave to feed the agent scoped, relevant context instead of making it crawl your whole domain every turn. - Scope what you put in the window. Claude’s per-turn cache re-read means a bloated context is a recurring bill, not a one-time one. Smaller, sharper context pays off every single turn.
- Prefer the generators.
mix ash.codegenand the igniter installers absorbed a huge amount of the boilerplate the agent would otherwise reason its way through one token at a time.
What I’d still want to know
This is one task, two models, a snapshot in time. Ash’s representation in model training will only improve; today’s tax is not a permanent property of the framework. A bigger, multi-feature task might amortize the comprehension cost or compound it — I genuinely don’t know which. And I measured tokens processed; the dollar gap is smaller than the token gap because Claude bills cache reads cheaply, so “2.6x the tokens” is not “2.6x the bill.”
If you reproduce it and get a different number, I want to hear about it. That’s what the repo is for.
The thing I actually took away
I went in to confirm a hunch about Ash. I came out thinking about something larger: as
agents become the default way code gets written, “how comprehensible is this to an AI”
is becoming a real axis of framework and documentation design — one we’ve barely started
measuring. The frameworks that win the agent era might not be the ones that are most
elegant for humans. They’ll be the ones that make their shape cheapest to learn, over and
over, in a fresh context window — which is exactly what usage_rules is quietly inventing.
Ash is paying a tax today. It’s also, with usage-rules, one of the few frameworks actively building the thing that pays it back down. Make of that what you will.
The benchmark, warts and all, is on GitHub. Tell me where I’m wrong.